关于我们
视觉方案
解决方案
公司产品
新闻资讯
联系我们
佳行申健智康科技有限公司聚焦于机器视觉技术在人体功能评价和健康管理领域的应用解决方案。公司将感知、认知、决策的核心技术闭环运用于跨场景、跨行业的智能健康解决方案中,全面提升效率和品质,让机器视觉技术真正造福于人类和社会,助推国家从数字化到智慧化转型升级。
Visual solutions
科学性
数字化
专业性
必要性
易用性
可扩展
区别于传统的以传感器为主的解决方案,通过人脸识...
视觉解决方案记录官兵训练考核的现场视频资料,确保...
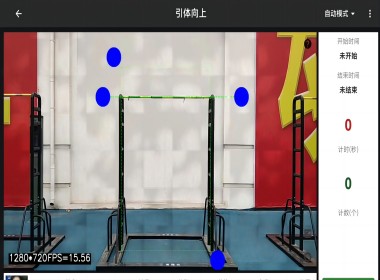
官兵在考核和训练的等环节,通过简单的手势即可完成...
视觉系统在系统结构上与目前的户外监控设备类似,成...
例如,对单兵长跑训练的视频流进行轨迹和身体关键点...
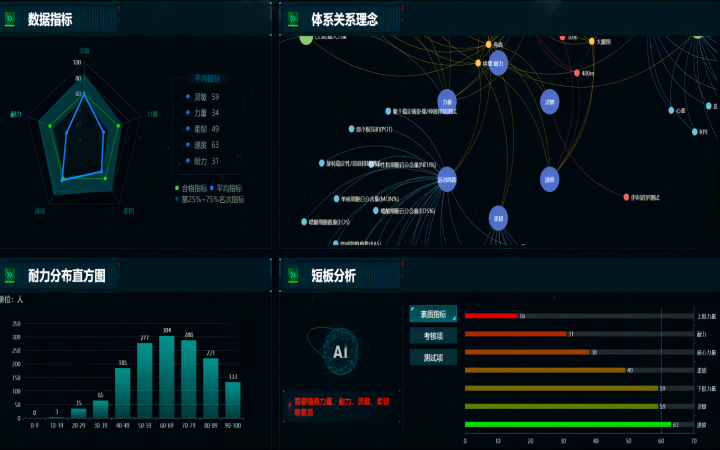
考核评估一体化系统由三个模块构成:体能考核模块、运动功能评估模块和综合分析模块。系统利用人工智能、大数据、机器视觉、...